
Hanya dalam 3 detik, AI yang belum pernah mendengar Anda berbicara dapat menirukan suara Anda dengan sempurna. Ini adalah pencapaian terbaru kecerdasan buatan Microsoft - model sintesis ucapan VALL-E, yang dapat menyalin suara siapa pun sesuka hati hanya dengan ucapan 3 detik.
Microsoft VALL-E akan meniru suara kita setelah hanya 3 detik berbicara
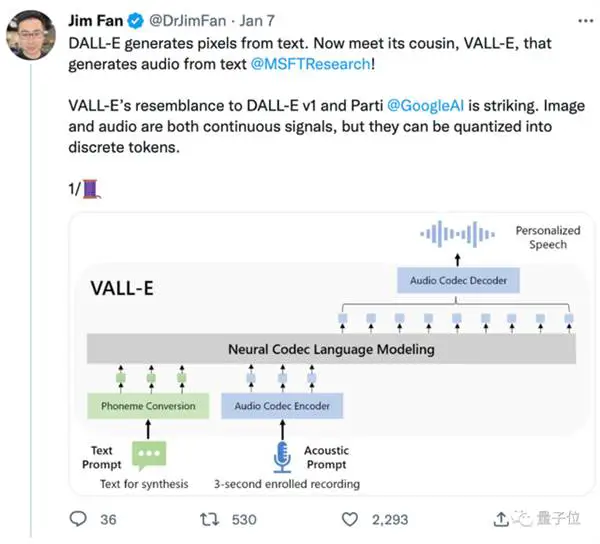
Itu berasal dari DALL E, tetapi berspesialisasi dalam bidang audio, dan efek text-to-speech menjadi populer setelah dirilis secara online.
Beberapa pengguna mengatakan bahwa jika VALL·E dan ChatGPT digabungkan, hasilnya akan luar biasa. Bagi yang lain, tampaknya hari yang memungkinkan untuk melakukan panggilan video dengan AI tidak lama lagi. Bahkan ada yang bercanda bahwa setelah AI mengurus penulis dan pelukis, selanjutnya adalah pengisi suara.

Namun, bagaimana VALL·E meniru suara yang “belum pernah terdengar” dalam 3 detik?
VALL-E menganalisis audio dengan model bahasa. Ini mensintesis ucapan berdasarkan suara "tidak terdengar" AI, yaitu pembelajaran tanpa sampel.
Solusi text-to-speech tradisional pada dasarnya adalah mode pra-latihan bersama dengan penyetelan halus. Jika digunakan dalam skenario sampel nol, itu akan menghasilkan kesamaan dan kealamian yang buruk dari ucapan yang dihasilkan.

Berdasarkan hal ini, VALL-E muncul entah dari mana, mengusulkan ide yang berbeda dari model vokal tradisional.
Dibandingkan dengan model tradisional yang menggunakan spektrum Mel untuk mengekstraksi fitur, VALL-E secara langsung mengambil sintesis ucapan sebagai tugas model bahasa, yang pertama kontinu dan yang kedua diskrit.
Secara khusus, proses sintesis ucapan tradisional seringkali merupakan jalur "fonem → mel-spektogram (mel-spektogram) → bentuk gelombang".
Tapi VALL -E mengubah proses ini menjadi “fonem → pengkodean audio diskrit → bentuk gelombang”:
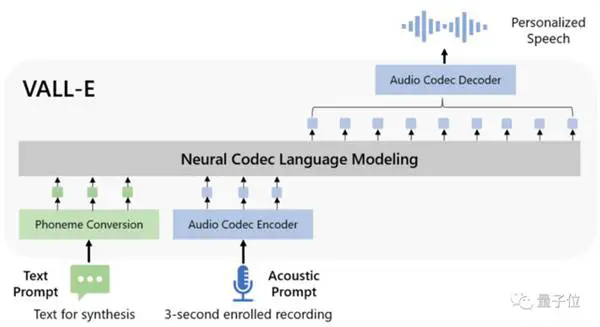
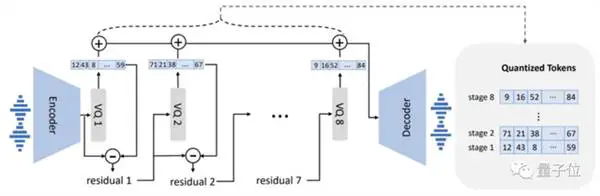
Dari segi desain model, VALL-E juga mirip dengan VQVAE. Kuantisasi audio menjadi serangkaian token diskrit. Quantizer pertama bertanggung jawab untuk menangkap konten audio dan karakteristik identitas pembicara, sedangkan quantizer kedua bertanggung jawab untuk penyempurnaan sinyal. yang terdengar lebih alami:
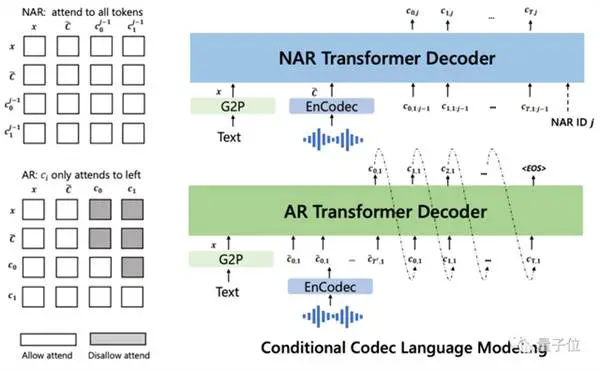
Kemudian dikondisikan oleh teks dan prompt audio 3 detik, secara otomatis menghasilkan pengkodean audio diskrit:
Namun tidak hanya itu, selain sintesis ucapan tanpa sampel, VALL-E juga mendukung pengeditan suara dan pembuatan konten suara yang digabungkan dengan GPT-3.
Suara latar sekitar juga dapat dipulihkan
Dilihat dari efek vokal yang disintesis, VALL-E dapat memulihkan lebih dari sekadar timbre pembicara.
Tidak hanya nada yang ditiru saat itu juga, tetapi juga mendukung berbagai kecepatan bicara yang berbeda. Misalnya, ini adalah dua kecepatan ucapan berbeda yang disediakan oleh VALL-E saat kalimat yang sama diucapkan dua kali, tetapi kemiripan tonalnya masih tinggi:
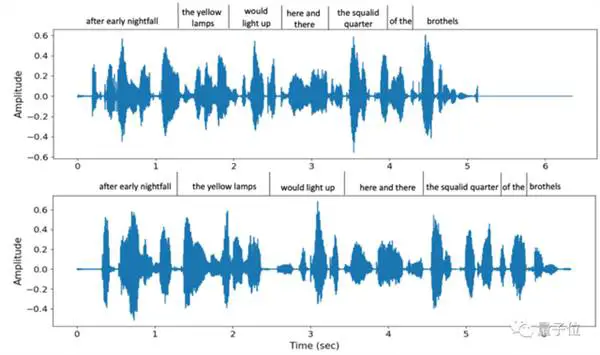
Pada saat yang sama, suara ambien latar belakang dari pihak lain juga dapat dipulihkan secara akurat.
Selain itu, VALL-E dapat meniru berbagai emosi pembicara, termasuk beberapa jenis seperti marah, mengantuk, netral, gembira, dan mual.
Perlu disebutkan bahwa kumpulan data yang digunakan untuk pelatihan VALL·E tidak terlalu besar.
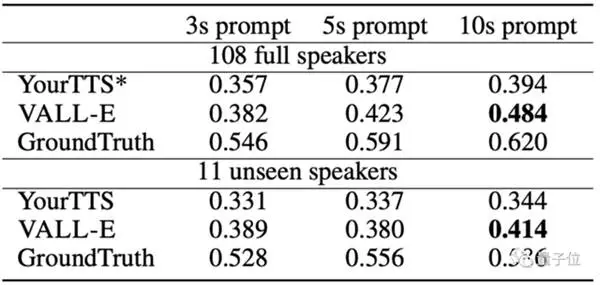
Dibandingkan dengan OpenAI's Whisper, yang membutuhkan 680.000 jam pelatihan audio dan hanya menggunakan lebih dari 7.000 speaker dan 60.000 jam pelatihan, VALL-E melampaui teks-ke-ucapan pra-pelatihan dalam hal kesamaan dengan teks-ke-ucapan Model YourTTS.
Selain itu, YourTTS mendengar suara 97 dari 108 speaker sebelumnya selama pelatihan, tetapi masih jauh dari VALL-E dalam pengujian yang sebenarnya.
Adapun bidang yang dapat diterapkan:
Tidak hanya dapat digunakan untuk meniru suara Anda sendiri, seperti membantu orang cacat menyelesaikan percakapan dengan orang lain, tetapi Anda juga dapat menggunakannya untuk berbicara saat Anda tidak menginginkannya. Tentu saja, itu juga dapat digunakan untuk merekam buku audio.
Namun, VALL-E belum open source dan Anda mungkin perlu menunggu sedikit lebih lama untuk mencobanya.
Ditawarkan di Amazon







